Friday, December 28, 2012
Generating Reports using Oracle Enterprise Scheduling Services (ESS)
Let me start of by stating that Oracle ESS does not provide any in-built mechanism or feature for generating reports. Oracle Business Intelligence Publisher (BIP) is the report generation and delivery engine for Fusion Applications and ESS simply takes advantage of this.
Here is some high level information on how ESS-BIP job submission works. The best part for application developers is that, they do not have to implement the code to invoke BIP from ESS; they just need to focus on defining the ESS job definition using BIP or Java JobType and specify the report attributes. ESS invokes the BIP agent API to submit a job report request, which will be picked up by the BI Publisher report processors. BIP agent API implementation internally calls asynchronous web service to generate data and process all delivery channels for that job report request. As part of ESS-BIP job submission, request parameters like requestId, job definition, job package name etc are updated in the ApplSession, which is propagated to the BIP server. Callback to the configured ESS web service happens after BIP finishes a report job.
ESS global submission user interface 'Output' tab provides options through which an end user can specify layout templates for reports, document formats (PDF, RTF), and report destinations (email, fax, printer). Depending on the file management group (FMG) property set for the ESS job definition, the relevant post-processing action is selected for the job. Post-processing actions can also be invoked programmatically from a client using a Java or web service API.
Also, you might want to check out the BI Publisher report bursting capability, where in report will slice the data to generate multiple output files by identifying required format and delivery options during report runtime. Each output can be delivered to multiple delivery channels. ESS Central Submission UI allows developers to specify bursting or non bursting using property name 'outputCollection' with value 'Y' or 'N'. Value 'N' indicates that no further BI report post processing action should be allowed.
Note that Report output (bursting and regular BIP report) will be stored in BIP repository.
As always, please refer the official Oracle ESS/Fusion Apps Developers Guide for more details.
Tuesday, November 27, 2012
Oracle ESS FND Data Security
In the Oracle Enterprise Scheduling Services (ESS) world, the mechanism to protect job request information is data security. ESS relies on the Oracle Fusion Data Security technology to implement data security and enforce security authorization for a specific data record or a set of records. Data security provides access control within Oracle Fusion applications on the data a user can access and the actions a user can perform on that data.
An overview of the high level steps involved in securing ESS request data is shown below:

Note: ESS Request History Access Control feature depends on FND_GRANTS, and so depends on FND_SESSION (application session). The application user session is the session that Oracle Fusion Data Security expects to see. Creating a ViewObject using ESS REQUEST HISTORY table will bypass ESS data security, as it is not protected by Virtual Private Database (VPD); and therefore it is strongly discouraged to do so. Moreover, this approach will lead to inconsistent behavior with ESS data security model.
Remember to always check the official Oracle ESS documentation for latest information on this topic ...
Monday, October 29, 2012
Systems Perspective on Software Development Project Cycle
The “Cloud” has become the dominant global trend in Enterprise IT today and the big question for many businesses is how to transform their IT model or adapt cloud initiatives to align with their strategy, structure and processes. I would like to take a step back and take a systems approach to analyze the challenges in the current software development life-cycle. I think a systems model will help in learning about the dynamic complexity of IT development projects and understand the sources of resistance to design more effective system models/policies for cloud transformation strategies.
I created a causal loop diagram to understand the challenges and relationships between different variables of the IT project cycle. The intent is to include sufficient number of key variables and their relationships to represent reality.
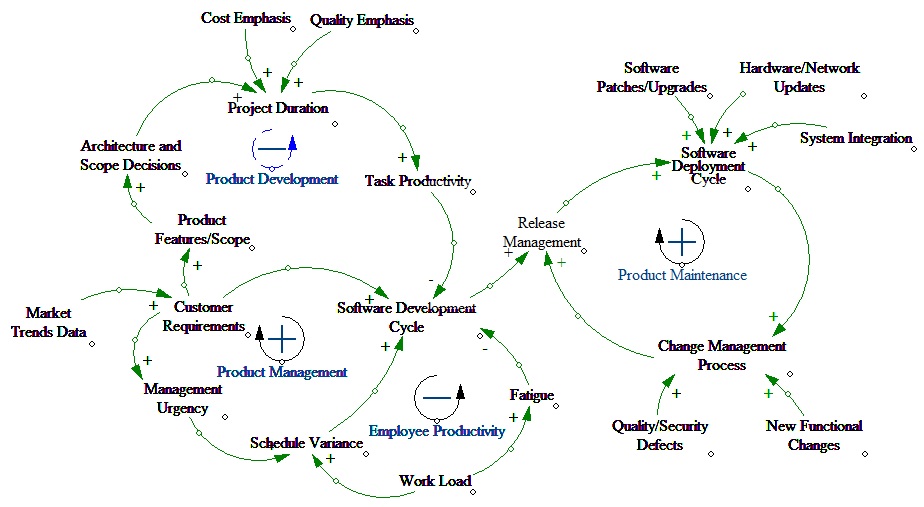
The Causal Loop Diagram shows four important loops:
1. Product Development (Balancing loop)
2. Product Management (Reinforcing loop)
3. Employee Productivity (Balancing loop)
4. Product Maintenance (Reinforcing loop)
The balancing Product Development loop illustrates that when there is an increase in customer requirements, need for scoping the existing software functionality and architectural design decisions increase as well. The reinforcing Product Management loop suggests that perturbations such as management actions can lead quickly to major changes in project schedule, prioritization and performance.
There is one key negative feedback loop - Employee Productivity. This loop reflects the assumption that if a task falls behind schedule or there is a critical customer requirement, management will direct workers to work overtime to put the task back on schedule in order to satisfy customer deadlines. The Product Maintenance loop represents the post development maintenance activities that involve deploying the software to meet customer business requirements.
Among other things, I think one of the significant advantages for software development teams will be to leverage the cloud vendor for the infrastructural related maintenance activities. Another causal loop diagram depicting the cloud IaaS/PaaS/SaaS model will reveal the finer details. Will get to it next ...
Sunday, September 30, 2012
Linking Congruence Model of Change with Balanced Scorecard and BPM
I recently came across David Nadler’s theory (1995) - Congruence model of Change. The proposed model is an open systems model based on the proposition that the effectiveness of an organization is determined by the congruence between the various elements of the organization. Congruence is "the degree to which the needs, demands, goals, objectives, and/or structures of one component are consistent with those of the other".
In analyzing the applicability of the congruence model, the inputs towards say, for example IT-Cloud transformation initiative for an organization, include the external environment, internal resources (e.g. people, knowledge skills, technology stack) and the organizations’ history. Based on these inputs, the executive management formulates the strategy for initiating changes in the IT delivery model. The outputs are the performance of the various sectors of the organization after the changes are implemented. I took a systems approach to depict the broad considerations and tools that can be utilized to drive the transformation processes.

1. INPUTS – Causal loop diagrams can be a good choice here to truly understand the organizational environment and the dynamic system by observing variables and their cause of variations.
2. Strategy - Kaplan & Norton' performance measurement framework ‘Balanced Scorecard’ can be used to align business activities to the vision and strategy of the organization, improve internal and external communications, and monitor organization performance against strategic goals.
3. Process Perspective – Business Process Management is a coherent and consistent way of understanding, modeling, analyzing, executing, monitoring and optimizing business processes as well as associated resources leading to business improvement. BPMN tools offered by Oracle SOA Suite can be employed here.
4. OUTPUTS – Business Intelligence and enterprise performance management tools deliver insights to help managers make better-informed decisions and are conducive to the enhancement of key performance indicators (KPIs).
Friday, August 24, 2012
Oracle ESS SubRequests
Oracle Enterprise Scheduler Services (ESS) provides a powerful and useful mechanism to process data in parallel - "Subrequests". The common use case is to employ ESS Subrequest feature for parallel execution of child jobs. For example, parallel processing of payroll for a large number of employees can be achieved by executing subjobs or child jobs i.e one job for each letter of the alphabet. This feature combined with ESS support for handling job dependencies (and incompatibilities - a ESS feature) will ensure that a payroll job does not run at the same time as a salary increase job.
In simple terms, an ESS job request is considered as a subrequest when a running job submits a new request, passing its own execution context. Passing the execution context ties the request being submitted to the currently running request.

Once a parent request submits a SubRequest, that parent must return control back to Oracle Enterprise Scheduler, in the manner appropriate for its job type, indicating that it has paused execution. Oracle Enterprise Scheduler then sets the parent state to PAUSED and starts processing the sub-request. Once the sub-request finishes, Oracle Enterprise Scheduler places the parent request on the ready queue, where it remains PAUSED, until it is picked up by an appropriate request processor. The parent is then set to RUNNING state and re-run as a resumed request.
In general, SubRequests are treated like any other request in regard to their processing. ESS will not automatically update the parent request status to ERROR on failure of a sub-request. It is up to the parent job to determine its own tolerance for sub-request failures and complete with the appropriate request status based on the outcome of the sub-requests.
Some important points to remember:
- ESS does not keep any kind of "ordering" in regard to subrequests submitted by a given execution of the parent request. Once the parent pauses, the processing of subrequests is like any other request; i.e., it is subject to workassignments, incompatibilities, async throttling, available worker threads, and so on
- There is no internal restriction imposed by ESS that limits how many sub-requests could be executing at a given time
- ESS WebService does not support sub-request submission
- Cross-cluster sub-requests are not possible
Monday, July 30, 2012
Monitoring application performance and stuff you can do with NetBeans and VisualVM
"Patience is a virtue" – probably not applicable when it comes to working with enterprise web applications, where the average web/mobile user expects pages to load in two seconds or less. The sheer complexity of IT environments handling high transaction volumes and complexity is the norm, and without application performance monitoring, it will be impossible to deliver consistent service levels.
As enterprise Java technology becomes more and more pervasive, understanding the behavior of the garbage collector becomes extremely important to monitor/manage application performance. Garbage Collection (GC) involves traversing Java heap spaces where application objects are allocated. So, it is important to know how frequently garbage collections are occurring and the time it takes for JVM to free memory no longer utilized by application logic. Heavy or excessive garbage collection will often show up as high CPU (the threads identified in high CPU will be the GC Threads).
The amount of time that garbage collection takes is related to the number of live objects in the heap space and not necessarily related to the size of a given Java heap size. The popular in-built or open source tools one can leverage to optimize the JVM for throughput and responsiveness are VisualVM (included with JDK 6 update 7 and later) and NetBeans Profiler.
Here is a list of performance monitoring/profiling stuff that can be performed using VisualVM and NetBeans:
- Capture sophisticated heap profiles using NetBeans profiler. Heap profiling is beneficial for observing frequent garbage collection and provides information about the memory allocation footprint of an application
- NetBeans CPU Profiling using bytecode instrumentation to profile the performance of an application
- Memory Profiling using VisualVM to analyze the memory usage of an application
- View live heap profiling results and traverse object references using NetBeans HeapWalker
- Visually observe garbage collector behavior using VisualVM plugin "VisualGC"
- Monitor surviving generations (or object age); an increasing number over a period of time can be a strong indicator of a memory leak
- Monitor Class loading and JIT compilation using VisualGC
- The number of threads that are currently active within your application, along with a drilldown of what type of threads that are in use
- VisualVM displays real-time, high-level data on thread activity, and thread dumps are very convenient to help diagnose a number of issues such as deadlocks or application hangs
- Analyze code fragment performance and identifying CPU bottlenecks using NetBeans
Monday, June 18, 2012
Why Distributed Caching Matters ...
My online shopping experience is limited to electronics and books, and the web site that provides good, fast and secure user experience invariably becomes my vendor of choice. For many web applications, consumers are likely to access the same data many, many times over the course of a day, and they all want fast concurrent access to, say item prices and other information. Behind the scenes, web and grid computing applications may repeatedly retrieve popular data, such as product descriptions, or they may create application-wide data, such as game scores, schedules, or interim stock trading results, all of which have to be accessible to all application servers deployed in a data grid. So, from a business perspective, it is important to recognize that there is an adverse impact on revenue when web page loads slowly and access to information is frustrated.
Challenges: A rising necessity to share more users’ session data between different Web applications, domains or application servers is a major challenge in designing distributed architecture. With the decline in exponential growth of CPU speed over the past few years, the onus is on the developers to wring out every microsecond of latency and to maximize application throughput. So, the paramount need for deploying high-performant web environments, is to move away from the methodology of having applications query the database or metadata store directly each time data is required to be retrieved, updated or passed around, to one where data lives closer to the application tier. This is where data grid solutions come in, where its innovations in distributed caching make their mark.
Business Solution: The main goal of Distributed Caching (or Data Grid) is to provide as much data as possible from memory on every grid node and to ensure data coherency (distributed transactions). By reliably staging application data in memory within the compute grid's memory, data is simultaneously available to all compute nodes with very low latency. This facilitates distributing application’s workloads and the result is many fewer round trips to the database and faster access to data at in-memory speeds.
Milliseconds translate to significant dollars spent or saved and distributed caching reduces not only the cost but also the risk as compared to scaling up lower data-tiers.For web applications, the in-memory data grid solution enables organizations to economically address data demand usecases involving repetitive reads/writes and session state management. In the era of cloud computing, caching (access to in-memory data) plays a pivotal role in the design of distributed systems.
Data Grid/Cache Vendors: Both commercial and open source offerings are available. JBoss Cache, GridGain and EhCache are some of the popular Java open source software for processing in-memory data. On the commercial side, for example, Oracle Coherence lets session states be managed in a variety of caching topologies and enables session data to be stored outside of Java EE application servers. This means that application server heap space is freed up and servers can restart without session data loss.
Browsing through the product offerings will generally give you an idea of the advantages and solutions readily available for leveraging important application performance gain, and why distributed caching matters.
Wednesday, May 30, 2012
A look at Android Architecture
Google’ Android documentation (http://developer.android.com/guide/basics/what-is-android.html) has come along pretty good. I now see that there is a
cool Android Architecture diagram that shows the major components of the
Android OS.
Summarizing the 10 notable aspects of the architecture that every
developer should be aware of:
1. Android is built on portable Linux platform that brings a level of
hardware abstraction
2. Android applications run as separate Linux processes with
security delegated to the underlying Linux system
3. The native libraries are C/C++ libraries and provides necessary services to the Android application layer
3. The native libraries are C/C++ libraries and provides necessary services to the Android application layer
4. Bionic standard C library is rewritten to make it license
friendly and purpose-built for tiny, battery-powered devices
5. Includes Apache Harmony, a modular Java runtime with class
libraries
6. Relies on Linux core kernel for memory management, power
management, and networking features
7. Java VM was replaced with the Dalvik Virtual Machine to
focus strictly on mobile devices and avoid licensing
8. Dalvik VM executes files in the Dalvik Executable (.dex)
format which is optimized for minimal memory footprint
9. Includes SQLite, a full featured relational database engine
available to all applications
10. 3D graphics is based
on the OpenGL ES 1.0 specification
Sunday, April 29, 2012
Android SDKs - Cupcake to Ice Cream Sandwich
My journey
with mobile’ leading development platform, Android started back in early 2011
with my first Android app (weekend project) in the marketplace - ‘tennis grand-slam
champions’. Ever since, I am keeping a tab on the Android platform and following
its feature offerings as time permits.
In the mobile development world, the release cycles are
considerably shorter than the traditional enterprise application development.
Android’ first stable version ‘Cupcake’ was released in April, 2009 and within couple
of years; we have seen many features evolved in ‘Ice Cream Sandwich – Android
SDK 4’. Éclair (v2) was better
optimized than Donut (v1.6) to take advantage of the hardware for faster
processing. Speed improvement was brought in with the
integration of Chrome V8 JavaScript engine and JIT optimization in Froyo (v2.2);
bluetooth and wi-fi made its way into the networking layer.
Gingerbread (v2.3) was
a major release and a considerable number of new features were introduced, that
include new UI themes, redesigned keyboards, new copy and paste functionality,
improved power management, NFC (Near Field Communication), support for VoIP/SIP
calls, new Camera application for accessing multiple cameras and supports
extra-large screens. Ice Cream Sandwich (v4) is much sleeker
than Gingerbread and Google has designed a font completely from the ground up,
which looks exceptional. Another major change is that a lot of the SQL handling
is moved from the native to the Java layer.
I am sure there are lots of articles on the web that will give a quick
comparison of the feature-sets that were bundled in every SDK release.
Saturday, March 24, 2012
Java Management Extensions and Weblogic Server MBeans
The best part I
like about Java Management Extensions (JMX) framework is that it allows
developers of applications, services, or devices to make their products
manageable in a standard way without having to understand or invest in complex
management systems.
JMX has been around as a core JEE API for a long time and is the
foundation for everything you can do to manage the Oracle Weblogic Server. The JMX architecture in the context of
Weblogic Server as I see it is shown in figure below:

Application
components designed with their management interface in mind can typically be
written as MBeans. WLS MBeans are 3 types - Domain, Server and Application
level MBeans. You can instrument your applications deployed to WLS by providing
one or more management beans. For example, the DomainRuntimeMBean provides a
federated view of all of the running JVMs in a Weblogic administrative domain.
All Weblogic Server MBeans can be organized into one of the following general
types - Runtime MBeans or Configuration MBeans based on whether the MBean
monitors the runtime state of a server or configures servers and JMX manageable
resources.
WLS MBean Server acts as a container for MBeans. The MBean
servers available in a Weblogic domain are:
- Runtime MBeanServer: is the MBeanServer available from any Weblogic process, and contains both Weblogic and user MBeans. Each server in the domain hosts an instance of this MBean server.
- Domain MBeanServer: This MBeanServer provides federated access to MBeans for domain-wide services. Collocated with the WLS domain admin server process, this server also acts as a single point of access for MBeans that reside on Managed Servers. So, as long as a managed server is up, its MBeans can be accessed through the "Domain Runtime" MBeanServer.
- Edit MBeanServer: Collocated with the WLS domain admin server process, it provides access to pending configuration MBeans and operations that control the configuration of a Weblogic Server domain. No application MBeans can be registered in this MBeanServer.
The JMX API enables to perform remote management of resources by
using JMX technology-based connectors (JMX connectors). Adaptors and connectors
make all MBean server operations available to a remote management application.
Fusion Applications Control (or commonly known as EM Console) is the primary
administration management interface. Developers can programmatically monitor
Weblogic Server by using the JMX interface directly in a Java program or by
writing scripts using a tool such as WLST.
Here is a good blog article on managing WLS using Jconsole: http://blogs.oracle.com/WebLogicServer/entry/managing_weblogic_servers_with
Please refer the Oracle Weblogic Server documentation for the
latest on WLS-MBeans.
Monday, February 27, 2012
An evaluation of Content Management Software Solutions
Content
Management Solutions (CMS) have evolved quite a lot in the recent years. There
are so many available, all with different features, it can easily be an
overwhelming task for any business or a web designer to choose the right
solution-fit for their project.
I took
upon myself to evaluate the CMS solutions that will be ideal for a small
organization, like church for example. From my research of web articles, blogs
and support forums the message I get is that a fully featured CMS, that is
stable with a clear roadmap for future development/feature enhancements and a
commitment to support and enhance the performance aspect is probably the best
way to go. Here is the tabulated evaluation matrix of some of the major elements
- cost, feature set and hosting options; that were important to me.

Table: Content Management Software Evaluation (January, 2012)
Sunday, January 8, 2012
Oracle ESS LifeCycle
My first post on Oracle ESS briefly introduced the high level functional aspects of the framework. Here, I will discuss the ESS request execution processing stages - a key concept to understand when working with ESS.
The lifecycle of an ESS Job Execution begins when the client makes a request for the job submission and ends when the server responds with the execution state. The lifecycle consists of three main phases: PreProcess, Execute and PostProcess.

During the PreProcess phase, several actions can take place. For instance, setting request properties for work/output/log directories, verficiation of ESS request file directory, creating application session (a lightweight session object in the Fusion Apps context), database connection initialization, using requested NLS settings, and loading environment properties file for spawned execution are some of the purposes of PreProcessing. PreProcessor will run prior to every job request execution, and when a request is restarted after pausing.
Executable phase is where the actual job program runs. The program logic can be implemented in any of the supported ESS JobTypes i.e. Java, C, PL/SQL, Host, Perl, SQL, BIP etc. For example, Java job logic runs in the context of the J2ee ESS application hosting the job metadata. On the other hand, PL/SQL program logic written as procedures are executed as an Oracle RDBMS Scheduler job procedure (owned by ESS runtime schema) after the ESS wrapper procedure does some initialization/set up work. In general, for any job type the post-process handler is called only after the ESS mid-tier is notified the request executable has ended.
PostProcessing is performed only if the overall processing of the ESS request gets as far as the executable stage and it completes as success or warning, Post-processing is not done if the pre-processing or executable fails as error, or if the request is cancelled prior to post-processing. The main purpose of PostProcessor is to carry out general cleanup tasks and other actions to reflect the final state of the request before the job request can be deemed as fully complete. PostProcessing runs after the job has completed its execution to perform defined actions, such as Notification (using Oracle UMS) and storing the request log/output files to the Content Repository (i.e. Oracle UCM Server).
Finally, here are some important points to remember w.r.t the ESS request lifecycle:
- If the pre-process handler returns an error status, the business logic for that request will not be executed for that execution attempt. The request will normally transition to an ERROR state from which it may be retried if RETRIES are configured. It is important to note that pre-processor is not guaranteed to run in the same thread as the executable.
- If post-processing is attempted and returns as error, the overall request state is set to WARNING. Post Processing will only occur after the request has gone to a terminal state.
Please refer the Oracle ESS Developers Guide for more details and latest information.
Subscribe to:
Posts (Atom)